


出品 | 搜狐科技
作者 | 梁昌均
编辑 | 杨锦
一口气开源8款模型,阿里通义又上新!
4月29日一大早,阿里开源发布Qwen3,包括两款MoE(混合专家架构)模型,其中具备2350亿参数规模的Qwen3-235B-A22B,在对比测试中成为目前最强大的开源模型。
此外,Qwen3还包括六款稠密模型,涵盖6亿、17亿、40亿、80亿、140亿和320亿等多参数,这些模型均未采用MoE设计,主打适配多场景。
“这才是真正的Open AI之道”“让开源再次伟大”……在坚持AI开源这条路上,阿里似乎又夺回了一度失去的话语权。
这也意味着,大模型技术还没卷到头,尤其是DeepSeek爆火以来,OpenAI、谷歌、Meta和阿里、百度、字节成为核心的PK力量,DeepSeek还在憋大招,开源的这把火要越烧越旺了。
以训练Agent为中心
阿里公布的测试显示,旗舰模型 Qwen3-235B-A22B (激活参数为220亿)在代码、数学、通用能力等基准测试中,媲美甚至超过DeepSeek-R1、o1、o3-mini、Grok-3和谷歌Gemini-2.5-Pro等顶级模型。
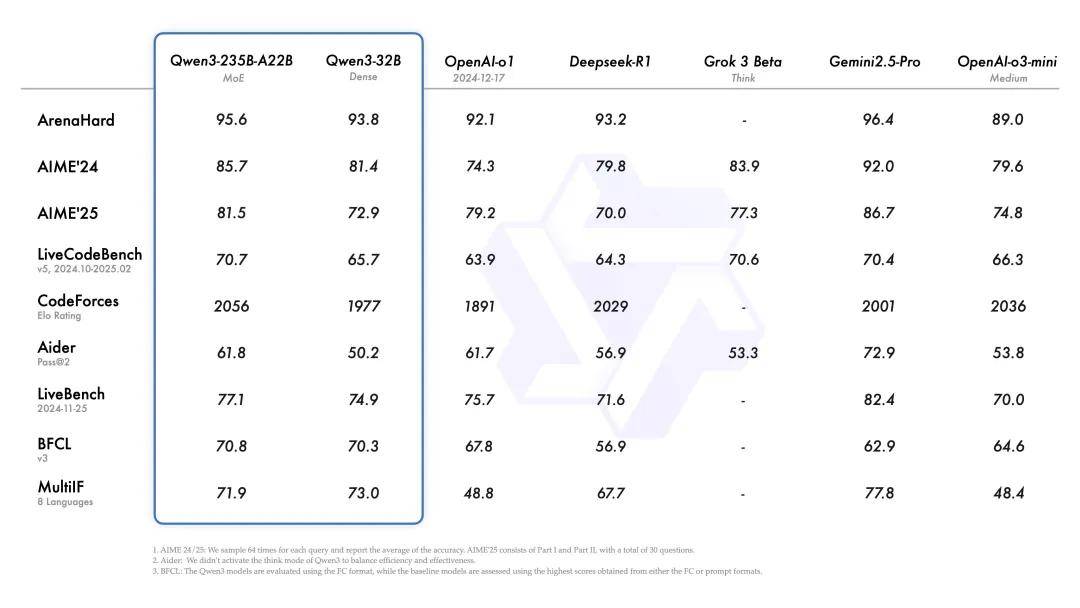
在大模型竞技场推出的综合能力评估ArenaHard、美国数学竞赛测试AIME24和AIME25,以及编程LiveCodeBench、CodeForces等九大测试中,Qwen3-235B-A22B的得分均超过DeepSeek-R1、o1、o3mimi、Grok-3,但部分表现仍不及Gemini-2.5-Pro。
同时,在主流开源模型中,Qwen3-235B-A22B也在通用任务、数学和科学任务、多语言任务和代码任务上,全面超越Meta在4月初发布的LLaMA-4-Maverick和DeepSeek-V3模型,成为目前最强大的开源模型。

值得一提的是,Qwen3-235B-A22B相对而言,参数规模更小,大约仅有R1和V3参数规模的(6710亿)的35%,同时低于o1(约3000亿)和LLaMA-4-Maverick(超4000亿),实现了小而美、以小博大的性能。
这样的能力同样体现在其它模型当中。另一款小型MoE模型Qwen3-30B-A3B的激活参数量仅有30亿,仅有QwQ-32B的10%,更远低于DeepSeek-V3(总参数6710亿、激活370亿)和GPT-4o的参数规模,在前述九项测试中表现更胜一筹。
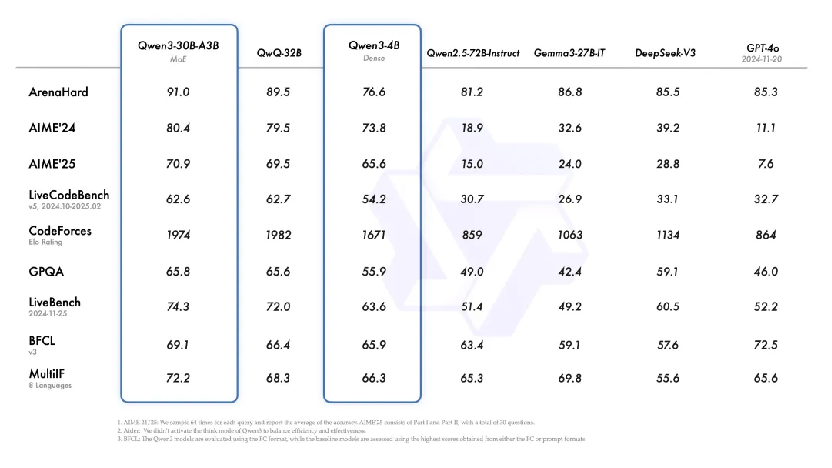
就连Qwen3-4B这样仅有40亿参数的模型,也能匹敌Qwen2.5中具有720亿参数模型的性能,数学、编码等测试也能超过DeepSeek-V3和GPT-4o。
Qwen3模型的一大亮点还在于,具备快思考和慢思考两种模式。对于需要深入思考的复杂问题,模型会逐步推理,经过深思熟虑后给出最终答案。对于速度有要求的简单问题,模型则提供快速、近乎即时的响应,让用户实现对模型思考程度的控制。
阿里通义团队认为,这两种模式的结合增强了模型实现稳定且高效的思考预算控制能力,让用户能够更好地为不同任务配置特定预算,在成本效益和推理质量之间实现更优的平衡。
同时,由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3稠密基础模型的性能与参数更多的Qwen2.5基础模型相当,从而节省了训练和推理成本。
数据显示,Qwen3-235B-A22B 仅需4张H20就能本地部署,而DeepSeek-R1推荐16卡H20配置,意味着Qwen 3旗舰模型部署成本相比R1下降七成多。
据阿里百炼平台,该模型API调用费用为4元/百万Token,和R1的4元/百万Token(缓存未命中)输入价格相当,远低于R1 16元/百万Token的输出价格。
此外,Qwen3模型还对Agent和代码能力进行了优化,推出了Qwen-Agent工具库,其封装了工具调用模板和解析器,降低了代码开发复杂度。此外,模型还支持最近火热的MCP(模型上下文协议),用户可以调用内置工具或自行集成其他工具。
此前,阿里云已推出MCP服务,并提出要做Agent Store。可以说,在智能体即将迎来爆发的时刻,阿里在模型、工具、应用上做好了全面准备。
比如,此次Qwen 3的六款稠密模型就能适配不同场景,包括科研侧、手机侧、汽车侧,以及开发者和企业大规模部署等。
“我们认为,我们正从专注于训练模型的时代过渡到以训练 Agent为中心的时代。”通义团队表示。
从Qwen3模型发布后的反馈来看,不少人都对其发出了称赞,认为这是目前最好的开源模型。“这是中国超越了自己,成为AI开源的新力量,意味着模型发展势头并没有放缓。”有海外用户提到,还有用户希望看到Qwen3与o3的测试对比。
当然,Qwen3模型似乎也并非完美。有用户表示,Qwen3在其个人评估测试中产生了好坏参半的结果,并且没有接近SOTA(最先进)。

该用户在使用开发框架Next.js进行TODO应用开发时,Qwen3-235B-A22B 与Claude 3.7 Sonnet和Gemini 2.5 Pro等顶级模型相当,代码运行没有问题,但没有严格遵循指令,生成的可视化内容因太小而难以阅读。
此外,多位用户还提到,Qwen3存在过度思考的问题,导致思考过程太长,而且默认的思维模式对更复杂的任务来说非常不可用,因此思考模式需要用户进行切换。
争夺大模型话语权
Qwen3模型性能的提升,得益于阿里通义团队在预训练和后训练上的多方面优化。
在预训练阶段,Qwen3的数据集达到约36万亿token,涵盖119种语言和方言,是Qwen2.5采用的数据集规模的两倍。这种规模在全球居于前列,如GPT-4、LLaMA-4等训练数据规模都在20万亿token之下。
Qwen3还使用了合成数据,比如为增加数学和代码数据,利用Qwen2.5的数学和代码模型,合成了包括教科书、问答对以及代码片段等多种形式的数据。
在后训练方面,在模型具备基本推理能力的基础上,通义团队利用大规模强化学习继续增强模型能力,还在指令遵循、格式遵循和Agent能力等20多个通用领域任务上应用了强化学习,在保证模型推理能力增强的同时,提高了通用能力。
“Qwen3代表了我们在通往通用人工智能和超级人工智能旅程中的一个重要里程碑。”通义团队表示,通过扩大预训练和强化学习的规模,实现了更高层次的智能。
该团队表示,未来计划从多个维度继续提升模型,包括优化模型架构和训练方法,实现扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围等目标,并利用环境反馈推进强化学习以进行长周期推理。
实际上,这也是目前国内外大模型正在追求的重点方向,如最近先后更新GPT-4o和o3的OpenAI,在多模态和推理能力方面进一步强化。
在阿里所坚持的模型开源这条路上,虽然Qwen系列模型此前超越Llama,成为全球第一开源模型家族。DeepSeek此前一度夺走了注意力,更是引发了新一轮的大模型技术竞赛。
这个月初,Meta开源最新的LLaMA-4模型,随后快速冲上Chatbot Arena 排行榜第二,仅次于Google刚发布的 Gemini 2.5 Pro。
但很快LLaMA-4面临利用公开测试集进行训练刷榜的质疑,有测试者还发现,在部分官方没有展示的基准测试中,其表现不尽人意。
当然,Meta方面予以否认,但承认模型性能存在参差不齐的问题。目前,规模最大、性能最强的LLaMA-4- Behemoth模型仍在训练中。Meta能否憋个大招扳回一局,还要再看看。
在憋大招的还有DeepSeek。随着阿里、百度、OpenAI、谷歌、Meta等先后推出最新模型,DeepSeek此前一度登顶的V3和R1模型失去绝对领先优势,全世界都在等待R2模型的推出。
此前3月有报道称,DeepSeek正在加快R2的研发和发布进程,原计划在5月初发布,但希望在3月中旬推出,当时这种说法遭到DeepSeek方面否认。
最近一个月,外界都在猜测R2何时会发布,根据业内产品迭代周期,不少看法认为会在5月,这可能意味着R2进入发布倒计时。
最新爆料称,R2依然采用MoE架构,拥有1.2万亿参数,成本GPT-4o便宜97.3%,视觉能力更强。
搜狐科技注意到,这在DeepSeek交流群引发了谈论,有观点认为,即便要发R2,也应该先发V4,R1正是以V3为基础而进行训练,但DeepSeek方面未对R2有关消息做出回应。
对阿里来说,开源是面对市场竞争的核心策略,但这也意味着只有性能做到领先,开源才有意义。正如DeepSeek一开源,就得到很多企业的主动适配和支持。
因此,对开源的AI企业来说,技术层面的持续进步就显得非常关键,这是推动应用爆发和生态构建的基础。随着阿里更新Qwen3模型,这一场AI开源的竞赛无疑又变得更加紧迫了。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏





